
Once upon a time I was use to listen a business requirement and automatically visualize its relational schema mapping nouns to entities/tables. I was proud of myself quickly defining a model with little logic, a service layer, business logic, an ORM library to manage et voila… something working showing it to the business stakeholders.
Let me visualize an example of it…
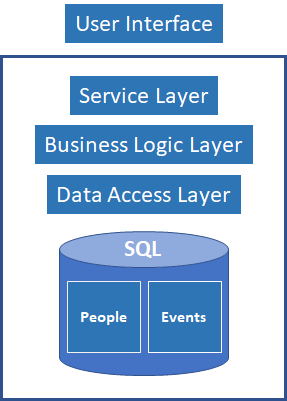
Is that wrong? No, it’s not. It’s a small monolith or a micro-service. As long as you keep it small, separate from other components and mitigate Db access problems with replicas it could work on medium/long term. You will still have RPC calls creating chains of exceptions across services but hey… there is logging and monitoring, and it doesn’t happen all the time especially while we initially develop it showing off to the business how fast we are.
It could be the fastest track to implement a solution. In a real scenario there are few more boxes but the basic is simple and understandable by any developer from junior to seasoned.
Personally, if I have a choice, I don’t do solutions in that way anymore. Reasons are varied and opinionable but I’m not going to extensively discuss that in this post.
Here I want to take the above 3 layers classic component architecture and inject Botox and apply lipstick so that it looks modern with all the distributed perks.
That usually happen when you have either a Solution Architect Astronaut (someone that doesn’t code but watch lot of Youtube videos) or a Seasoned Developer with no big-picture capabilities but willing to show some modern fritz.
Relational DB’s are outdated… let’s use No-Sql
I remember being a young developer looking at the relational theories from E. F. Codd and falling in love with them. What could go wrong they looks like rock solid. Again, I don’t think in that way anymore but it’s not the topic for this post.
One of the main benefits of relational theories is the possibility to construct all sort of complex queries. That is finally what the business wants right? Good reporting and analysis out of our data. Also, for processing you need to retrieve the current data in different ways and do it a fast pace.
Unfortunately, that doesn’t go well with the current trends flowing around Linkedin or Twitter. Everyone seems to talk about Cloud Native Event Driven Micro-Services.
How “Native” could be a solution based on 50 years old theories like Sql-Server or Postgres or MySql? These where working ages before the Cloud on bare metal servers and they have been just ported to the Cloud. For a new shiny solution… why not pick a Cloud Native storage service like AWS DynamoDb or Azure CosmosDb. Yeah, why not…
Let me visualize our simple 3 layers with the No-Sql perk

The problem with that is about retrieving the data. These key/value tools are good for storing documents and retrieving them with a key. Is that good for our business requirements? It rarely is.
The origin of AWS Dynamo Db are dated back when AWS was initially created. It is still being used by AWS to store all the Cloud data and metadata. Key/Value No-Sql they serve scenarios where you have the key (example it’s the one attached to the current user) and you want to quickly retrieve all the related settings and metadata. But if your use case makes necessary querying the data in different and increasing complex ways, stay away from these two. They will be expensive and ways slower than proper relational dB’s.
I’ve also seen one Architect Astronaut designing the use of AWS DynamoDb in a relational way. Yes… sticking into a row/field json objects with related data. Basically, each single DynamoDb row has complex object like an hidden matryoshka trying to easier the retrieval of data. Without even consider performances, how I can maintain changes to the schema while requirements keep changing?
Instead of use No-Sql attached to the old patterns, it’s probably time to revisit these patterns around your logic and eventually stop to be data centric and shift toward a behavioural centric approach (read: DDD, Event Driven, CQRS). Once you get it then pick the right storage for the specific part of the job. For example, Elastic Search or Redis for the query part and an append only event store or even mongo-db for the write model part. Each of these store need to be carefully considered to pick the right one.
If that change is too big or you don’t like it, better to stick with old good relational dB’s.
Let’s make it Event Driven
With the first camouflage in place, the next is the attempt to be Event Driven.
Let me visualize the previous 3 camouflaged layers with the additional Event Driven perk

There are different ways and tools for implementing Event Driven solutions. What is important is to get the mechanics of messages flowing around right. To get it right I had to make mistakes and go back and forth with practice while studying it from different angles. I have to make a clear distinction of messages between Commands and Events. I had to mess with 1:1 or 1:N communication patterns in order to put the available tools in the right box in the big picture. I had to practice the horizontal scaling provided by at-least-once with the hurdle of idempotency. And all the rest of it.
Event Driven by accident happen when we just publish events with no much thinking about the necessary surrounding patterns and practices. We have written something in our store, let’s publish an event.
What happen if the Event publish fail? What happen if the event disappears from the topic after a while and the consumer need it again? What happen if on the other side the consumer processes the event and perform a payment and you re-send the same event? What if the consumer want to read the data in a consistent way?
To mitigate all the drawback that can derive from having events there are patterns and practices like outbox pattern, creating local cache out of events, persisting events in a permanent event store and replay them any time is needed and so on.
If we don’t want this complexity of implement Event Driven patterns and practices around tooling, then better to just stick with the original 3 layer architecture and expose data and behaviours through API/RPC calls.
You must be logged in to post a comment.